AWS AutoML Lite - Serverless AutoML Platform
Cost-effective AutoML platform built on AWS serverless architecture. Upload CSV files, automatically detect problem types (classification/regression), train ML models with FLAML, and deploy for serverless inference via Lambda + ONNX Runtime. ~$3-25/month vs ~$36-171/month for SageMaker endpoints.
Overview
A lightweight AutoML platform built on AWS serverless services. Features split architecture: FastAPI + Mangum for Lambda API (5MB) and Docker containers on AWS Batch Fargate Spot for training (265MB ML dependencies). Built with Python 3.11+, Next.js 16, and Terraform 1.9+. Implements automatic problem type detection, EDA report generation with ydata-profiling, intelligent feature preprocessing (ID column detection, constant/duplicate removal), serverless model inference with ONNX Runtime on Lambda ($0 idle vs ~$36-171/month SageMaker), model export (.pkl and .onnx), model comparison of up to 4 training runs, dark mode with system preference detection, and training run tags/notes for experiment organization. Infrastructure as Code with Terraform. Frontend with SSR deployed on AWS Amplify (Node.js 20+). Achieves ~$3-25/month cost ($0 when idle) with complete CI/CD via GitHub Actions OIDC.
Technologies & Tools
Architecture & System Design

Main architecture: Split design with Lambda API (5MB) and AWS Batch containers for ML training (265MB)

Data flow: CSV upload → S3 → Lambda preprocessing → Batch training → S3 model storage

Training pipeline: AWS Batch Fargate Spot with Docker containers running FLAML AutoML

CI/CD: GitHub Actions with OIDC for secure AWS authentication and Terraform deployments
Performance Metrics

Model evaluation metrics: Accuracy, F1-Score, Precision, Recall for classification (R², RMSE, MAE for regression)
Application Screenshots

Configuration UI with column selection, auto problem type detection (Classification/Regression), and excluded columns

Real-time training progress with AWS Batch job status tracking
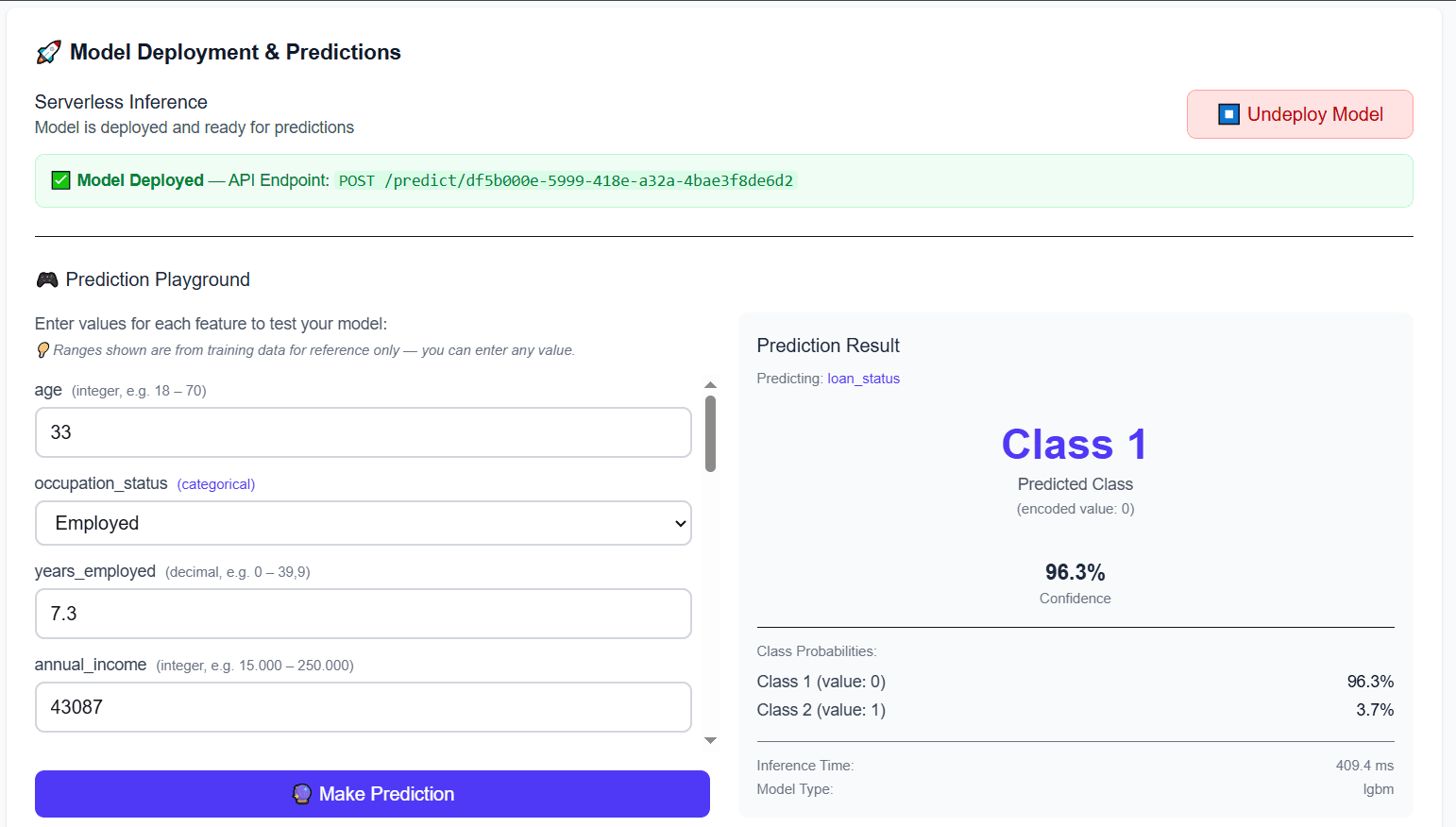
Prediction Playground: Interactive form with serverless Lambda + ONNX inference, showing class prediction with probabilities
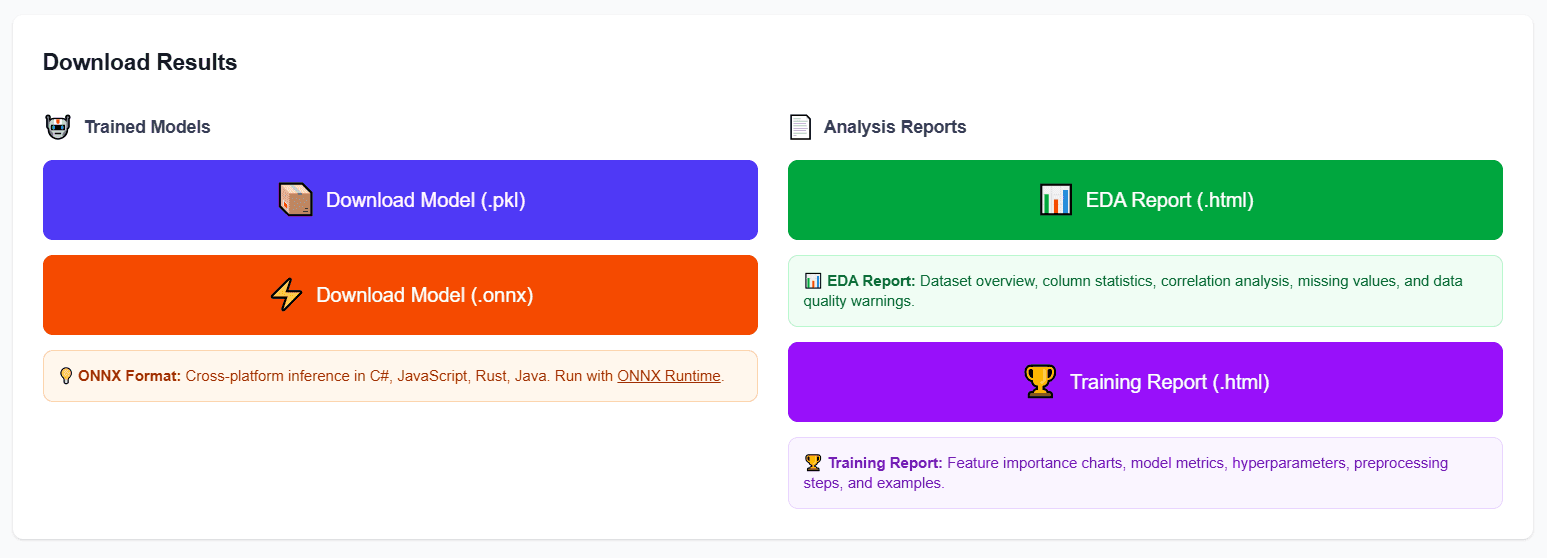
Download models (.pkl and .onnx formats) with Docker and Python usage instructions
Additional Resources

Automated EDA report generated with ydata-profiling showing dataset overview and alerts

Training report with best model summary, metrics, and hyperparameters
Key Features
- 1Serverless Model Inference: One-click deploy models for predictions via Lambda + ONNX Runtime ($0 idle vs ~$36-171/month SageMaker)
- 2Prediction Playground: Interactive UI to test deployed models with real-time predictions and confidence scores
- 3ONNX Model Export: Cross-platform model format (.onnx) alongside .pkl for portable deployment
- 4Model Comparison: Side-by-side comparison of up to 4 training runs with metrics highlighting
- 5Dark Mode: Full theme support with system preference detection and manual toggle
- 6Training Tags & Notes: Organize and annotate experiments with custom tags (up to 10) and notes (up to 1000 chars)
Challenges & Solutions
Lambda Package Size Limits for ML Dependencies
Challenge: Initial attempts to deploy ML training code directly in Lambda failed due to the 250MB deployment package limit. ML dependencies (FLAML, scikit-learn, xgboost, lightgbm) totaled ~265MB, exceeding Lambda limits.
Solution: Implemented split architecture: Lambda handles API requests (5MB compressed), AWS Batch runs training in Docker containers (no size limit). This also resolved the 15-minute timeout constraint for long-running training jobs (2-60 minutes). Cost analysis showed Batch Fargate Spot is 92% cheaper than Lambda for training workloads.
Low Model Accuracy Due to Irrelevant Features
Challenge: Initial training run showed only 35.98% accuracy. Investigation revealed the model was trying to learn from random identifiers (Order_ID, Customer_ID) that provided no predictive value.
Solution: Integrated feature-engine library with custom ID pattern detection using regex patterns (.*_?id$, ^id_?.*, etc.). Combined with constant feature detection (>98% same value) and duplicate feature removal. Result: Successfully auto-detected and excluded identifier columns, dramatically improving model accuracy.
Container Isolation and Environment Variable Cascade
Challenge: Training container initially tried to call the API for configuration, causing circular dependencies and network issues. The container needed to operate autonomously without API access.
Solution: Established environment variable cascade: Terraform (lambda.tf) → Lambda env vars → batch_service.py containerOverrides → train.py os.getenv(). Training container receives ALL context via environment variables and writes directly to DynamoDB/S3. Added validation in train.py to fail fast with clear error messages for missing variables.
Project Information
Timeline
Started: Nov 2025
Last updated: Dec 2025
Role
Full Stack Developer + AI/ML Engineer
Project Metrics
~$3-25
Monthly Cost
$36-171/mo
SageMaker Equivalent
$0
Idle Cost
4
ML Algorithms
<2s
Lambda Cold Start